Showing 101 of 101on this page. Filters & sort apply to loaded results; URL updates for sharing.101 of 101 on this page
LLM Inference - NVIDIA RTX GPU Performance | Puget Systems
Mastering LLM Techniques: Inference Optimization | NVIDIA Technical Blog
LLM Inference Optimization Techniques: A Comprehensive Analysis | by ...
The State of LLM Reasoning Model Inference
LLM Inference Optimization Overview - From Data to System Architecture
LLM Online Inference You Can Count On
Navigating the Intricacies of LLM Inference & Serving - Gradient Flow
LayerSkip: faster LLM Inference with Early Exit and Self-speculative ...
Top NVIDIA GPUs for LLM Inference | by Bijit Ghosh | Medium
LLM Inference Series: 5. Dissecting model performance | by Pierre ...
Figure 3 from Efficient LLM inference solution on Intel GPU | Semantic ...
LLM Inference Series: 2. The two-phase process behind LLMs’ responses ...
LLM Inference Series: 1. Introduction | by Pierre Lienhart | Medium
LLM Inference Optimization: Challenges, benefits (+ checklist)
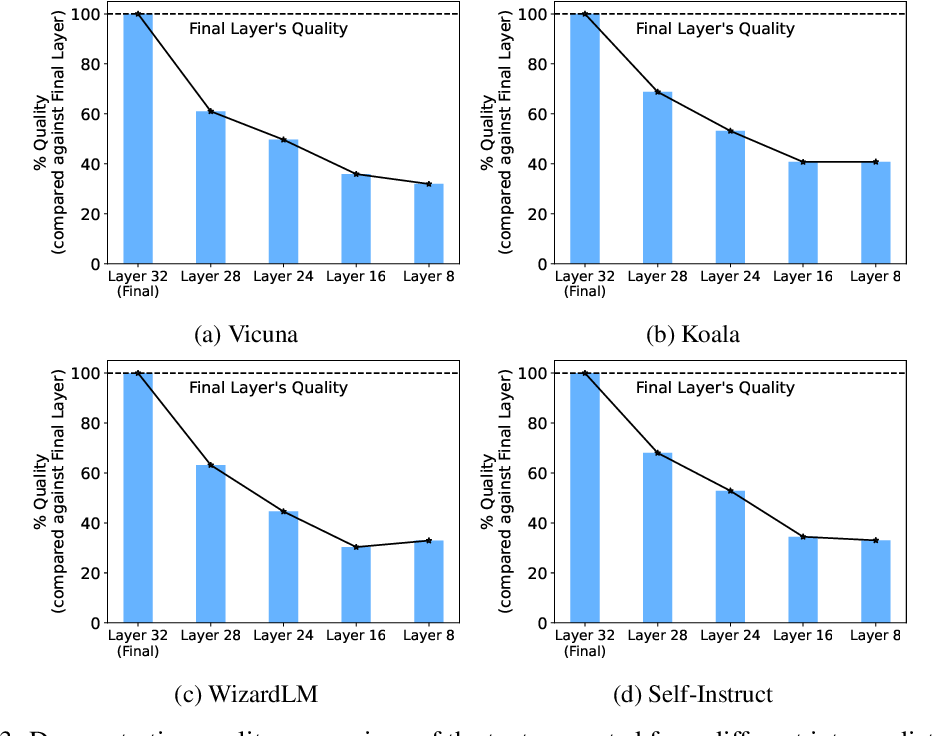
Figure 3 from Accelerating LLM Inference by Enabling Intermediate Layer ...
LLM Inference — A Detailed Breakdown of Transformer Architecture and ...
LLM Inference Benchmarking: Fundamental Concepts | NVIDIA Technical Blog
How does LLM inference work? | LLM Inference Handbook
Fast, Secure and Reliable: Enterprise-grade LLM Inference | Databricks Blog
Splitwise improves GPU usage by splitting LLM inference phases ...
LLM Inference Series: 4. KV caching, a deeper look | by Pierre Lienhart ...
Speculative Decoding — Make LLM Inference Faster | Medium | AI Science
A quick guide to LLM inference
Vidur: A Large-Scale Simulation Framework for LLM Inference Performance ...
LLM Inference on multiple GPUs with 🤗 Accelerate | by Geronimo | Medium
Figure 1 from Efficient LLM inference solution on Intel GPU | Semantic ...
Accelerating LLM Inference with Speculative Decoding using LMStudio ...
LLM Optimization for Inference - Techniques, Examples
LLM Inference Sizing: Benchmarking End-to-End Inference Systems S62797 ...
Enhancing LLM Inference on Mid-Range GPUs through Parallelization and ...
Boosting LLM Inference Speed: High Performance, Zero Compromise | by ...
LLM Inference 串讲-CSDN博客
List: Llm inference | Curated by Bader | Medium
Unlocking LLM Performance: Advanced Inference Optimization Techniques ...
Understanding LLM Inference: How AI Generates Words | DataCamp
The Best NVIDIA GPUs for LLM Inference: A Comprehensive Guide | by ...
The Future of Serverless Inference for Large Language Models – Unite.AI
Understanding the Two Key Stages of LLM Inference: Prefill and Decode ...
Decoding LLM Inference: A Deep Dive into Workloads, Optimization, and ...
LLM Inference: Understanding How Models Generate Responses Until We ...
How to Optimize LLM Inference: A Comprehensive Guide
Primer on Large Language Model (LLM) Inference Optimizations: 1 ...
LLM for Graph Learning 经典工作一览 - 知乎
Ways to Optimize LLM Inference: Boost Response Time, Amplify Throughput ...
Mastering the Art of LLM Inference: How to Fine-Tune Parameters for ...
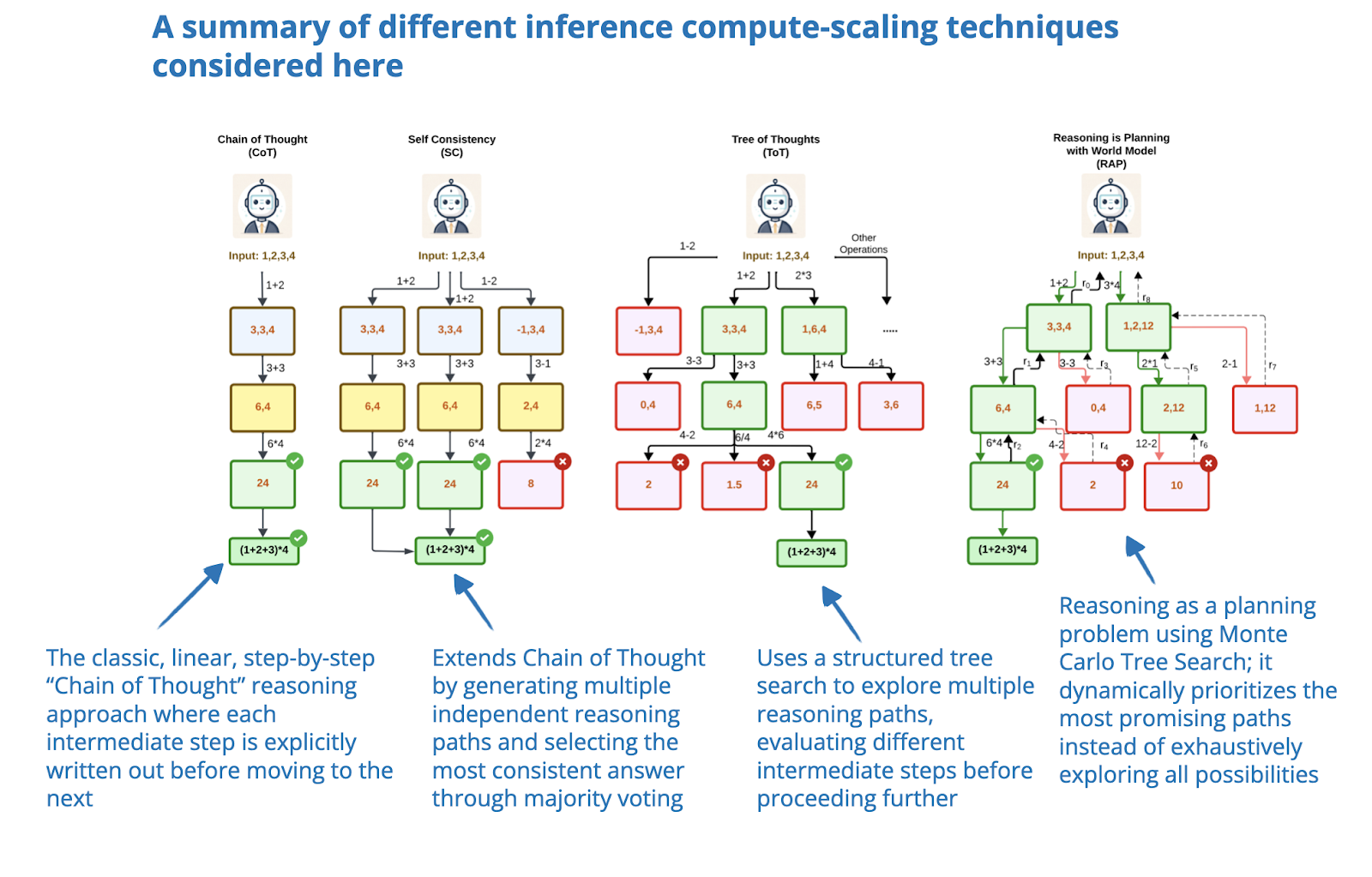
Meta Adaptive Ranking Model: Bending the Inference Scaling Curve to ...
NVIDIA RTX PRO 5000 Blackwell Workstation Edition 72GB GDDR7 Graphics ...
How to Run a Local LLM on Windows (No Cloud Required) | CORSAIR
5. Output: Designing the Delivery and Presentation of LLM Responses ...
Why Choose NVIDIA H100 SXM for Peak AI Performance
llm-inference · PyPI
GitHub - xlite-dev/Awesome-LLM-Inference: 📚A curated list of Awesome ...
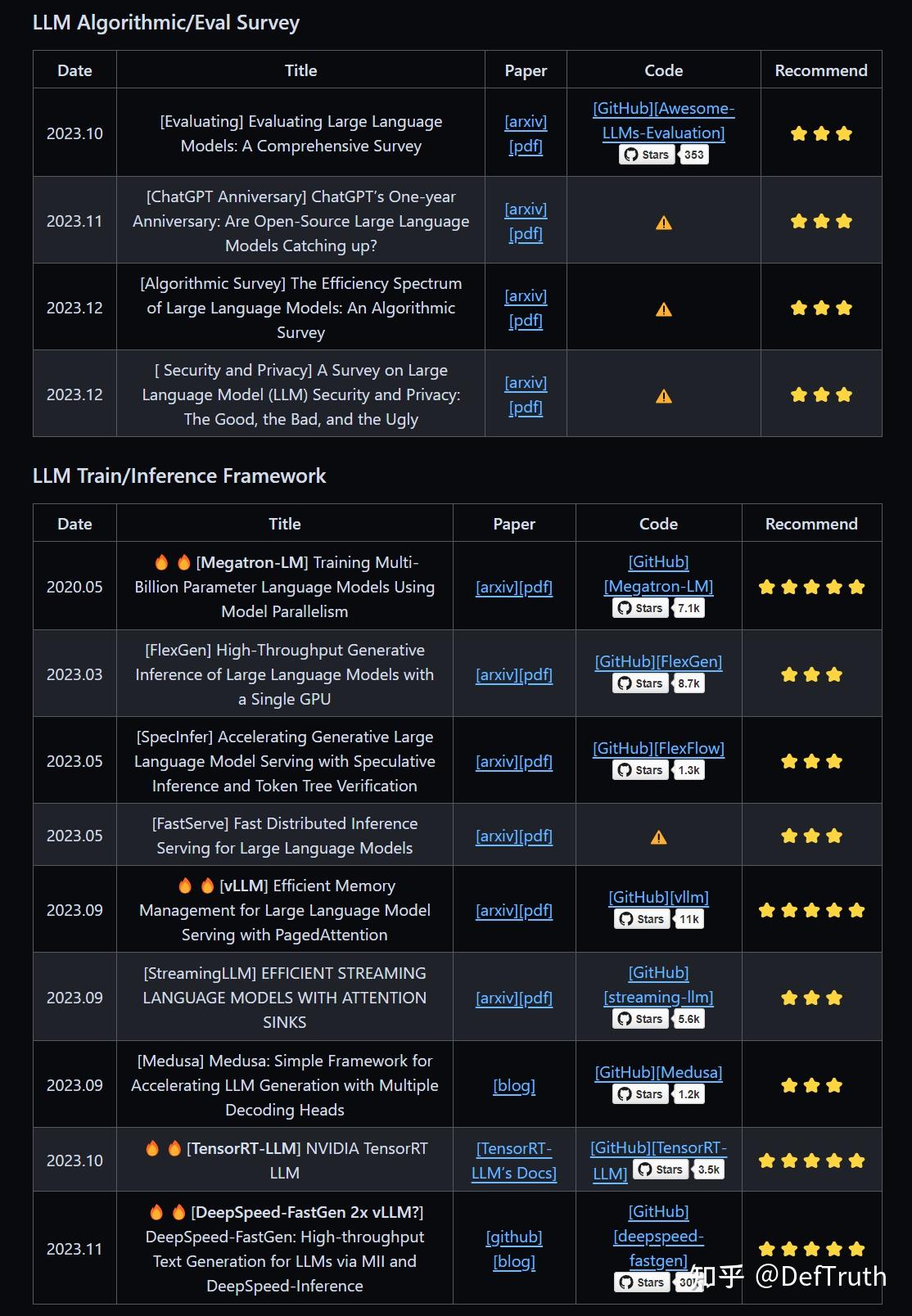
[Awesome-LLM-Inference]🔥第三期:30篇,LLM推理论文集-500页PDF💡 - 知乎
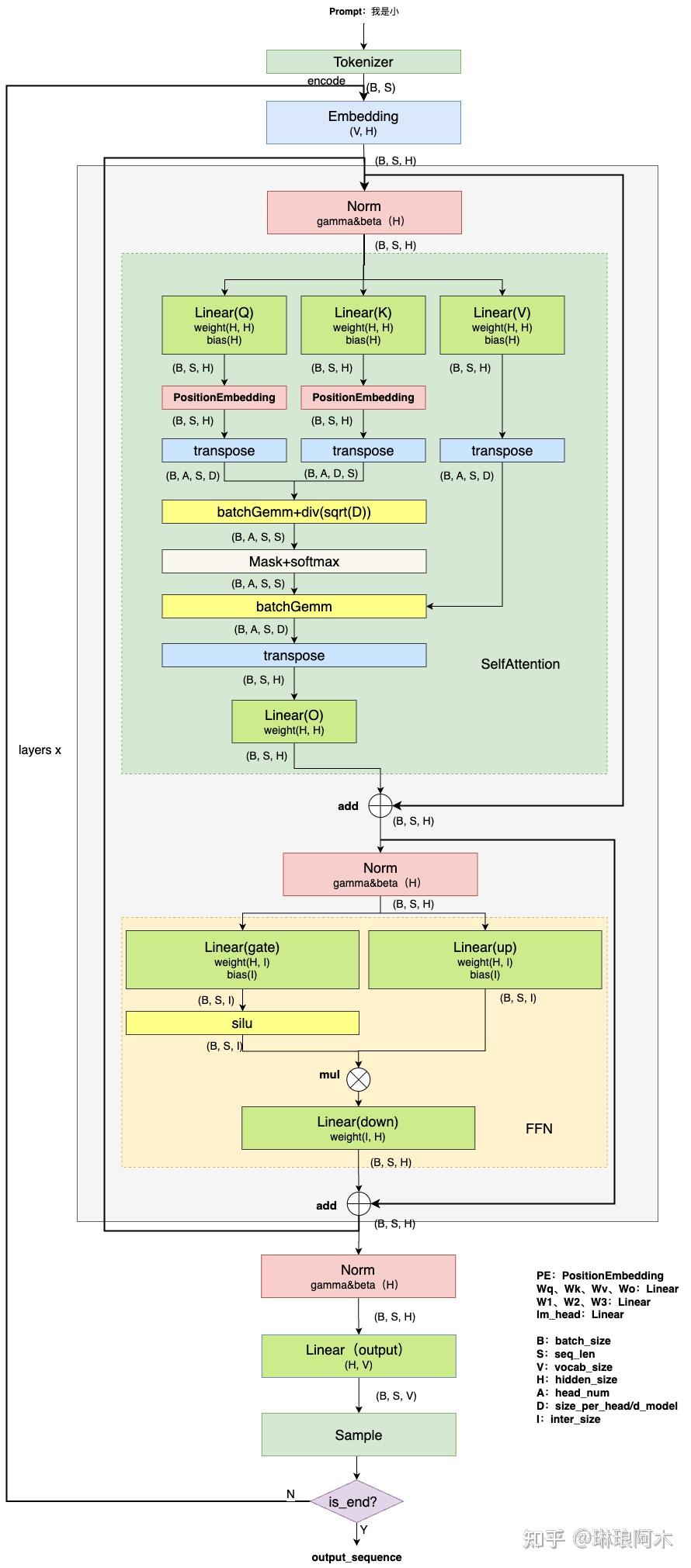
图文详解LLM inference:LLM模型架构详解 - 知乎
Why Every Token Costs More Than You Think | by delimitter | Mar, 2026 ...
A two-step concept-based approach for enhanced interpretability and ...
If you’ve ever wondered what these complex AI terms mean, this is the ...
Is the Nvidia RTX 5070 worth buying for gaming?
📊 This chart explains the high-end consumer GPU market right now 👇 🤖 ...
DLSS 4 vs FSR 4: How AI-Powered GPUs Are Transforming Gaming and Local ...
$INTC Intel’s CES 2026 product and platform narrative centered on Core ...
How Much VRAM Do You Need to Run Local LLMs?
Best Workstation Laptops 2024: Top Picks for Pros | Archyde – Memesita
Apriel 5B: Small Enterprise Language Model - Workflow™
Nintendo detalla los beneficios de jugar en Switch 2 a Tomodachi Life ...
TinyGPU Brings NVIDIA and AMD eGPUs to Apple Silicon Macs
BOBYFIA (@Bobyfiakill) / Posts / X
AMD Rolls Out Full Support for Google’s Gemma 4 AI Model Across Its ...
Linkblog - 2026-03-22 - D'Arcy Norman, PhD
Page 57: Fresher Jobs | Noida | Remote | Internshala



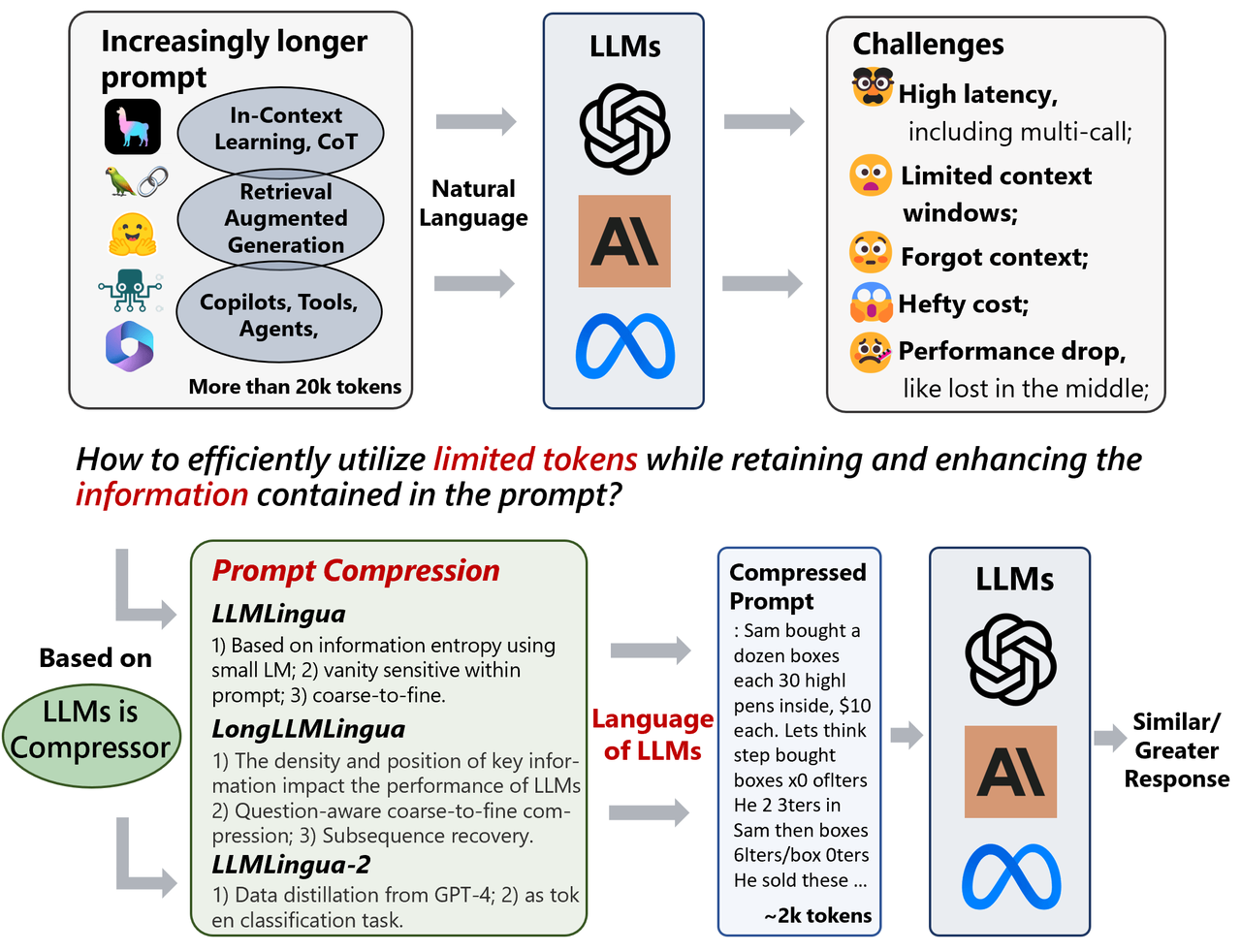


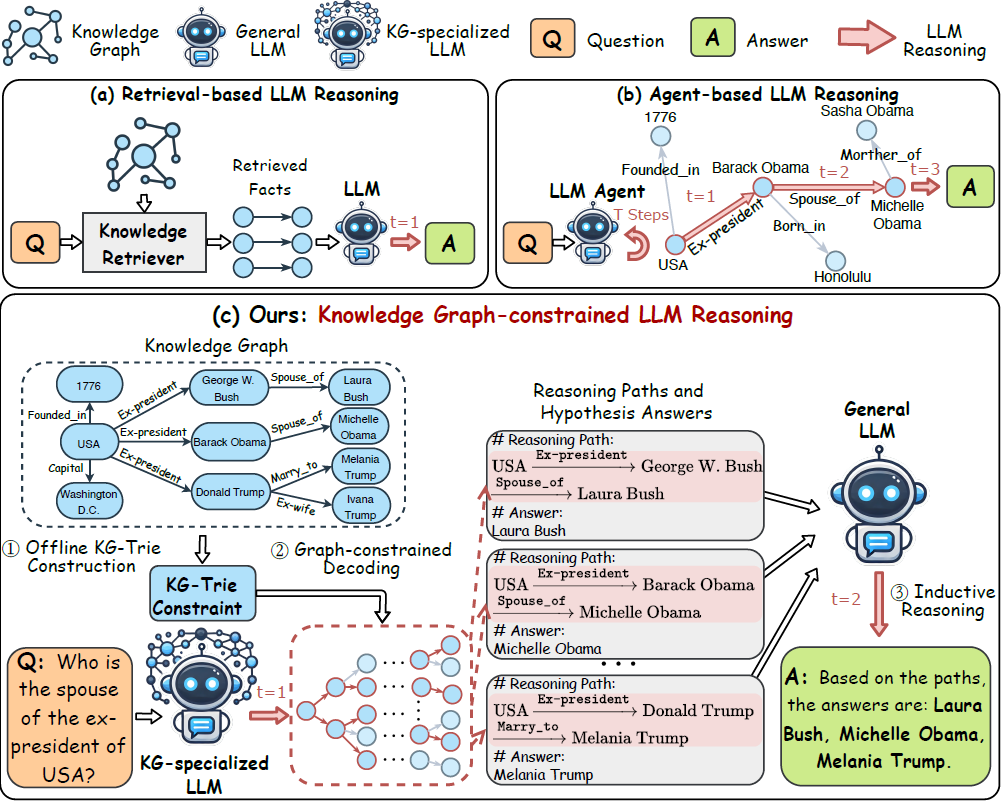
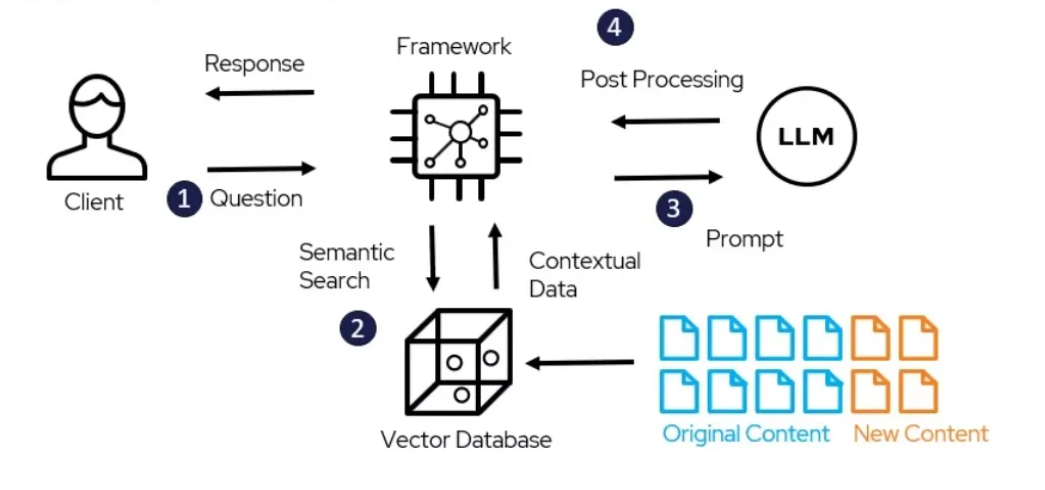
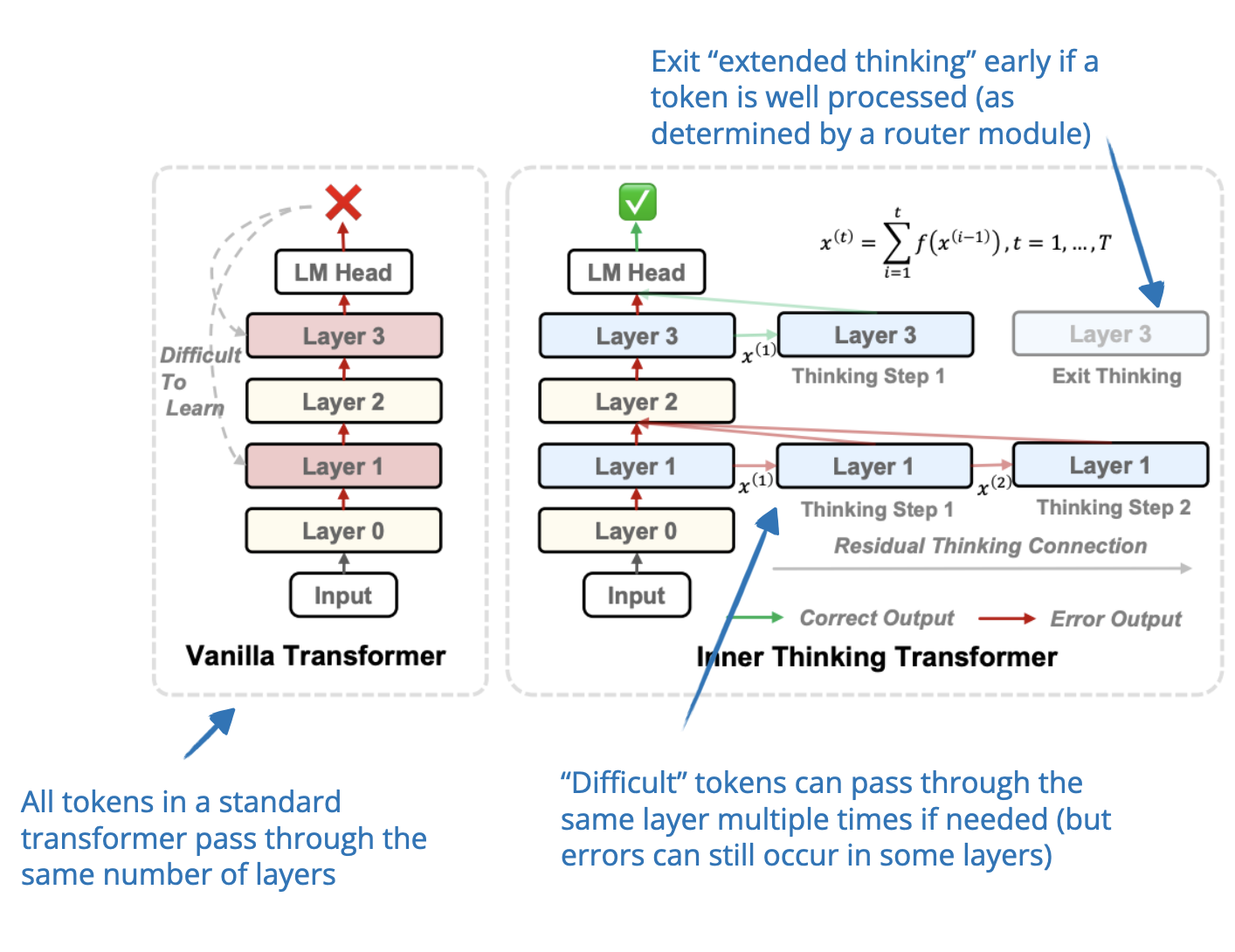
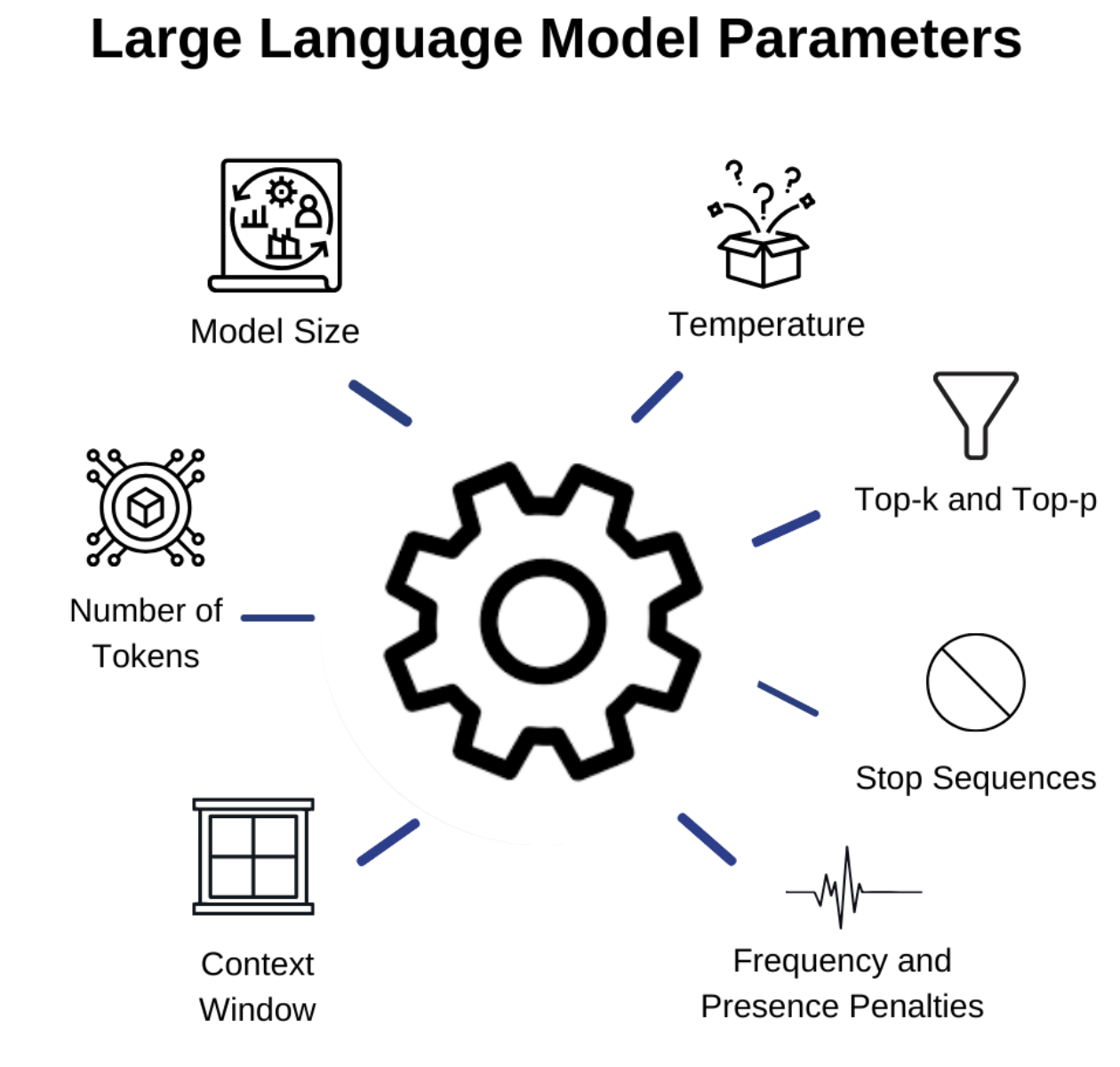



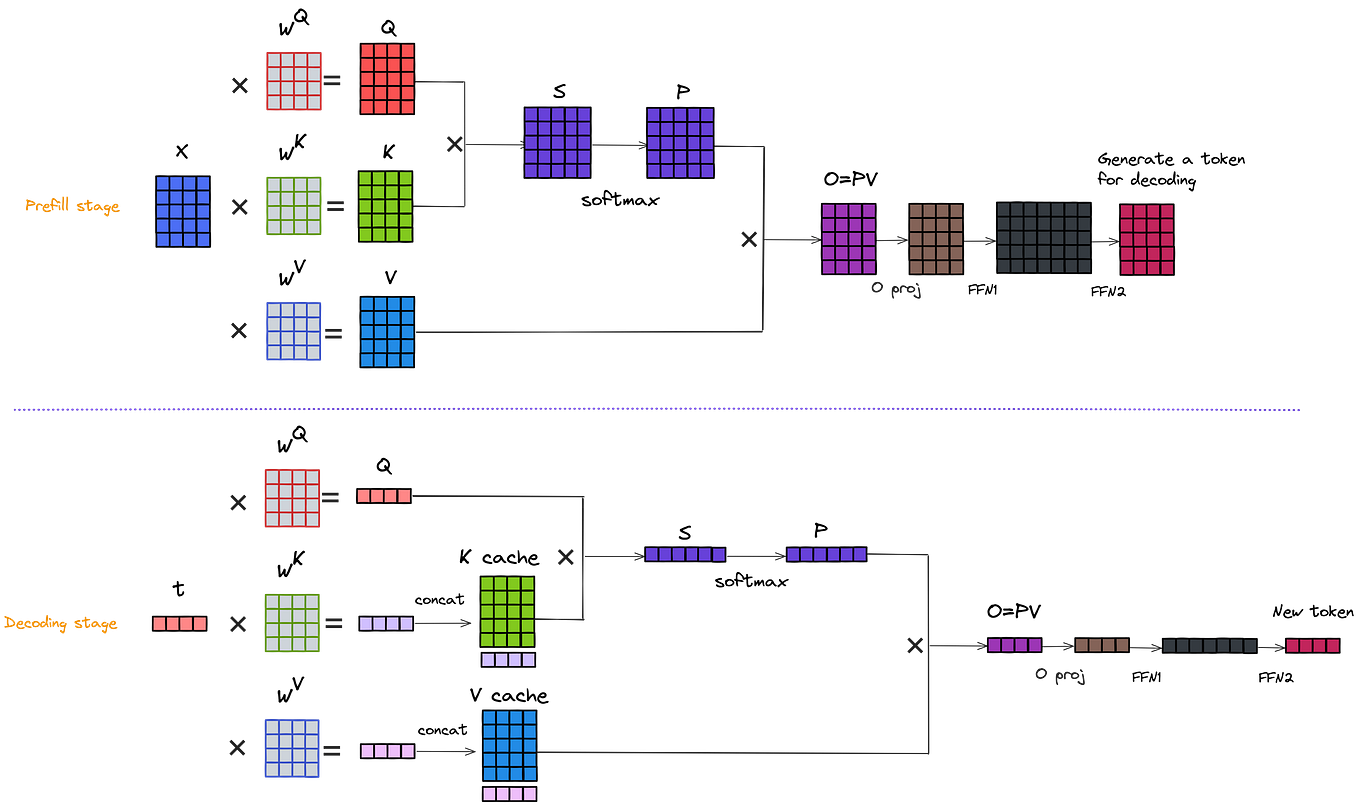

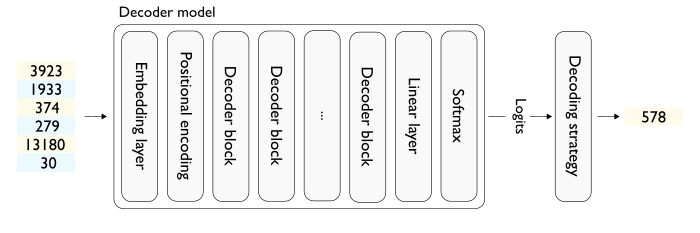

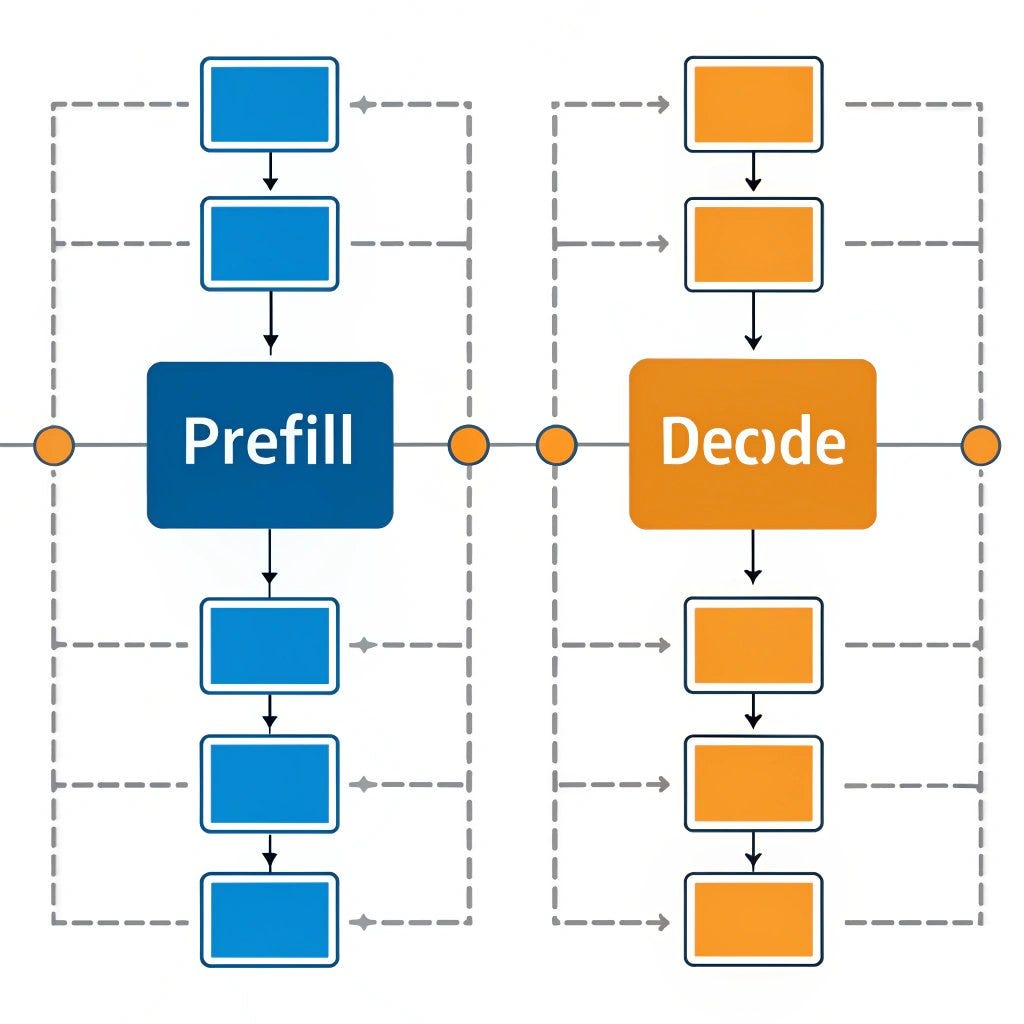
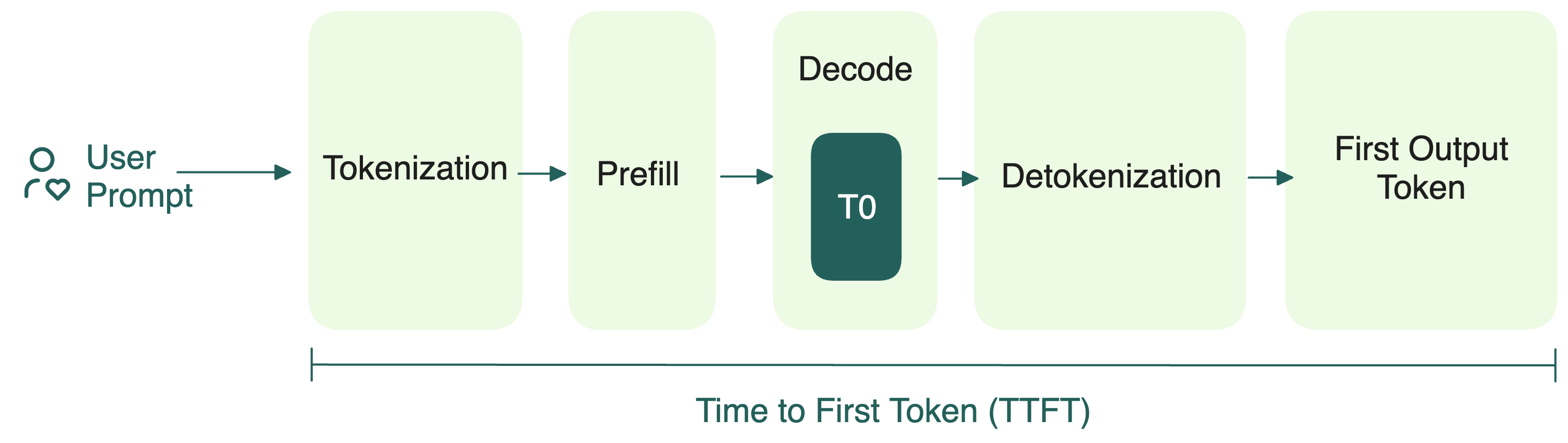

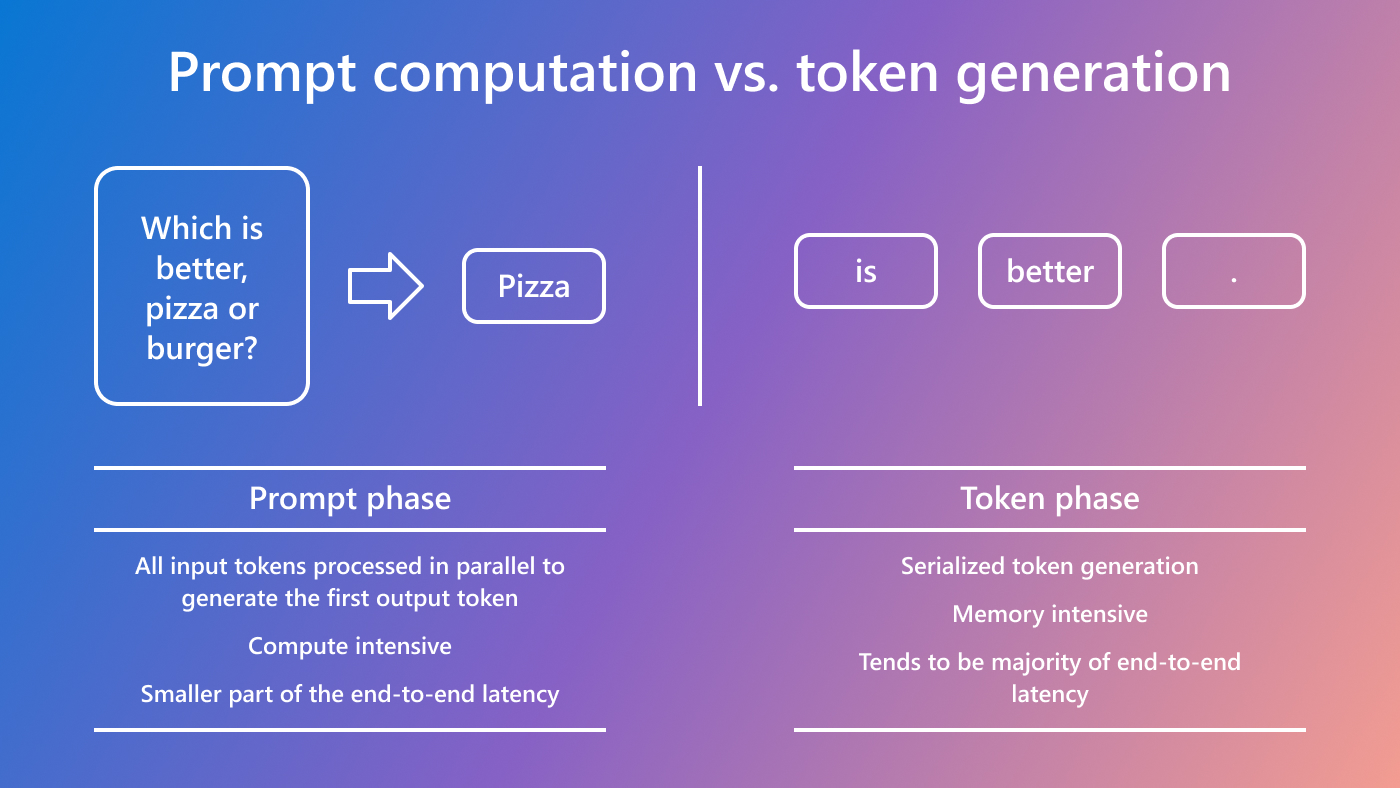
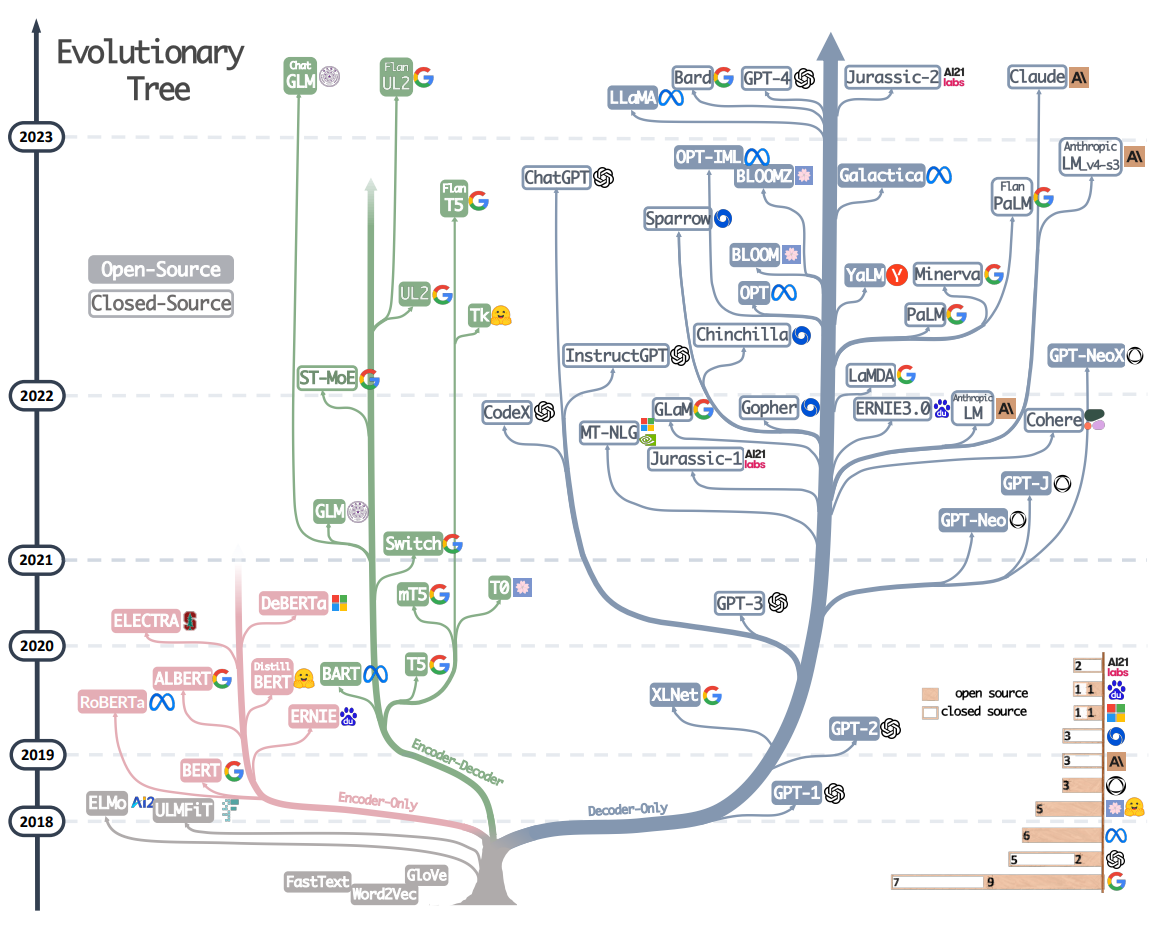





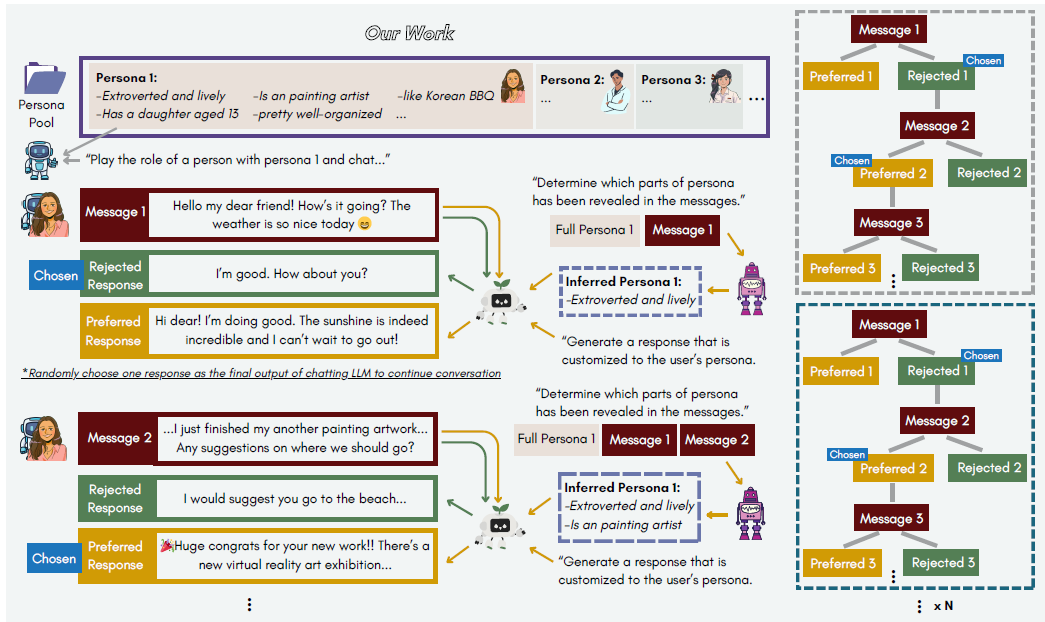




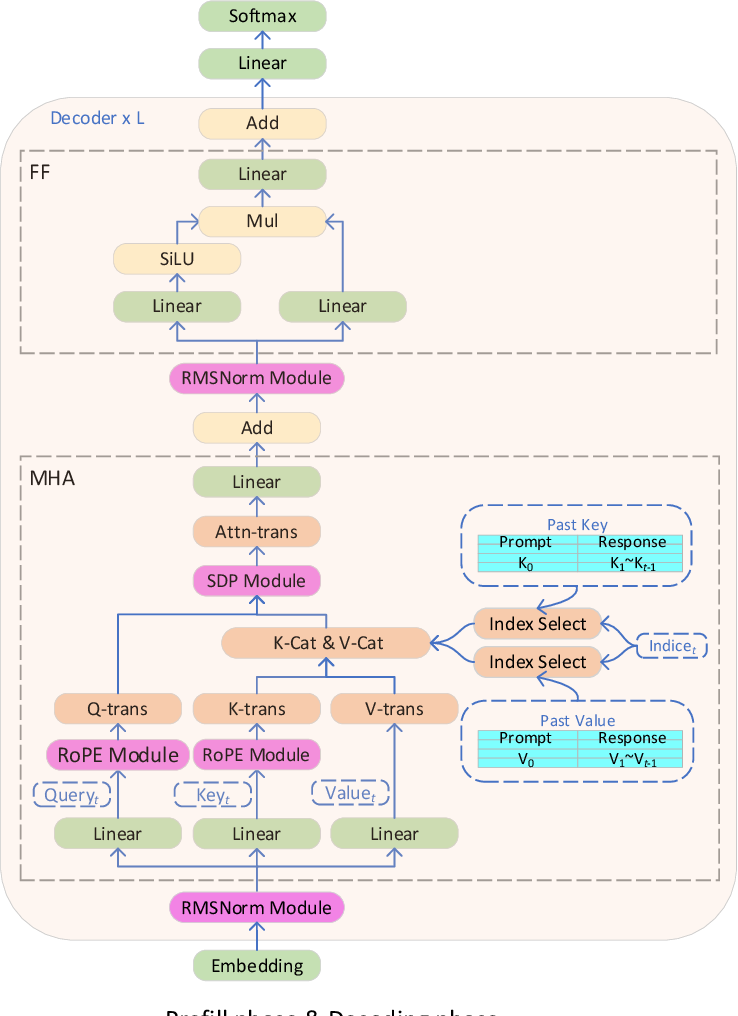

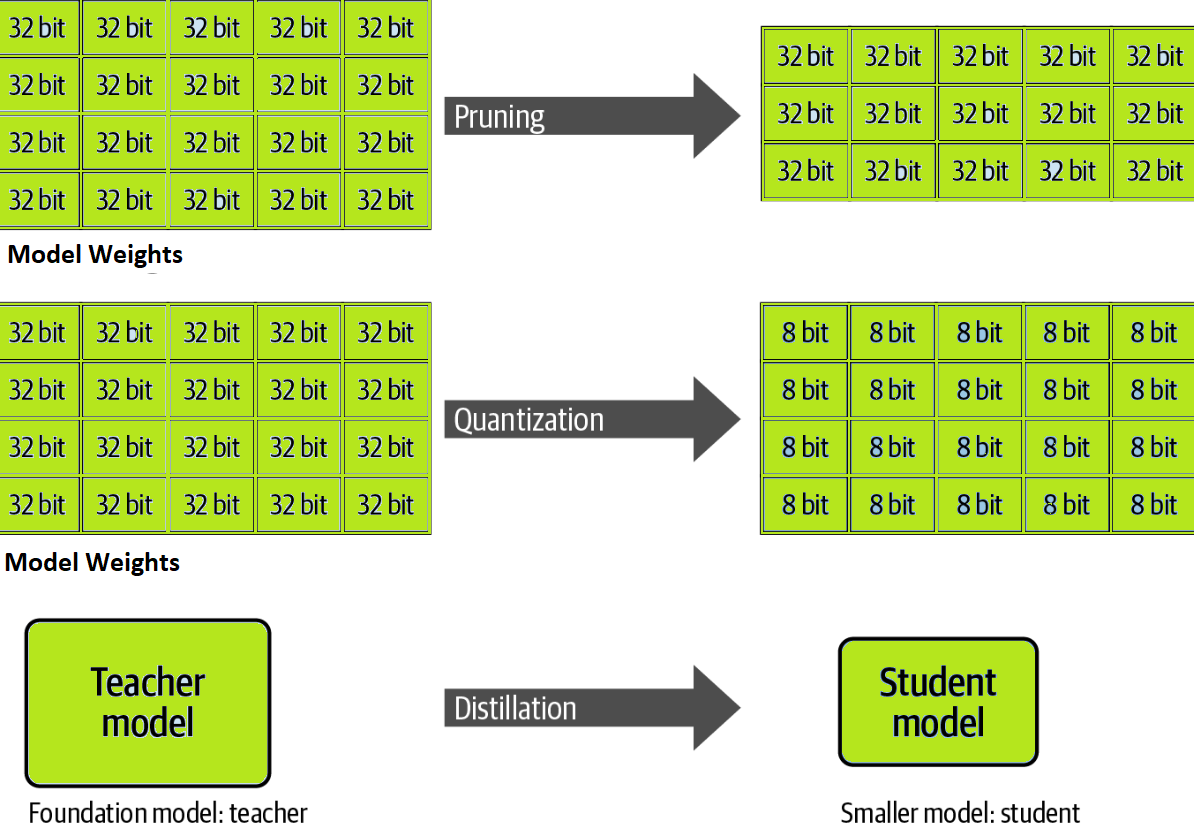


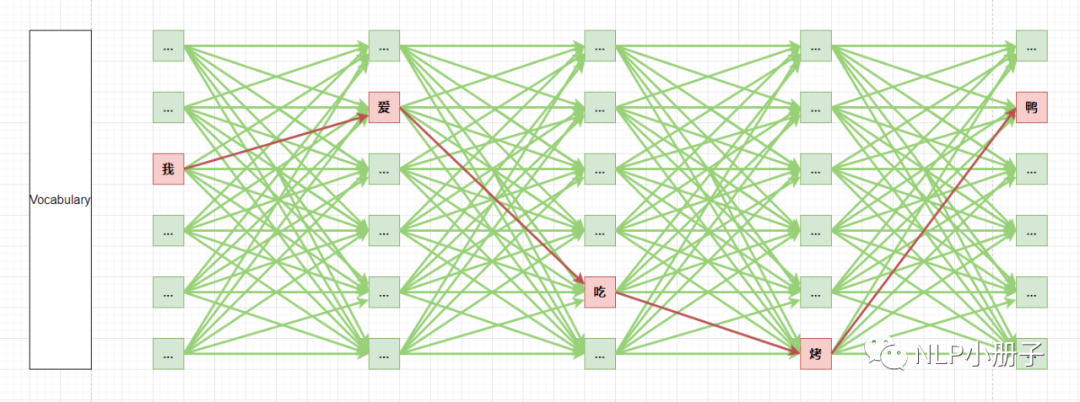
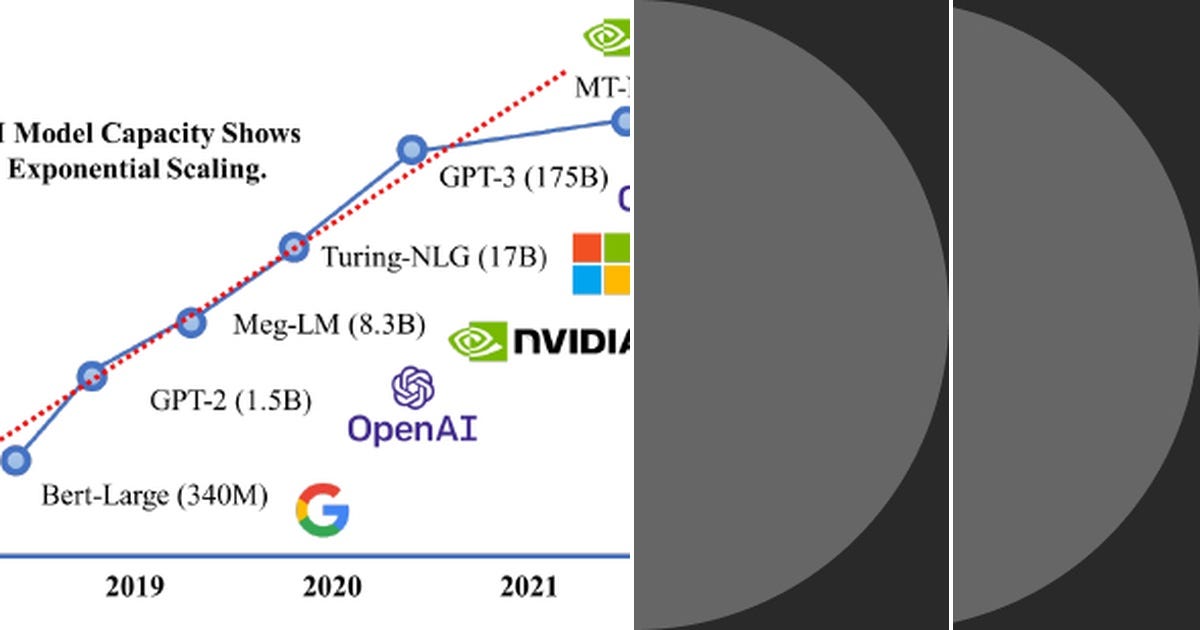
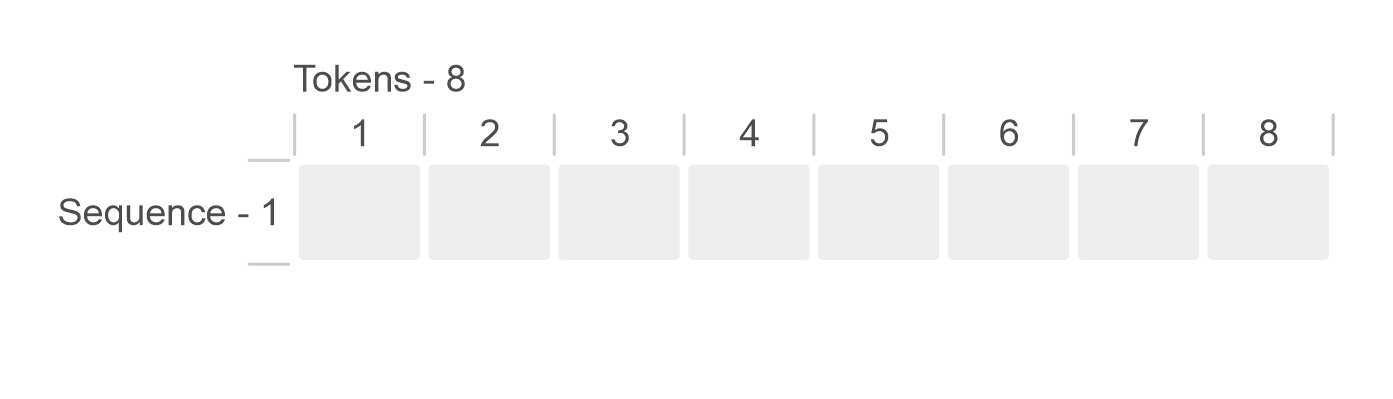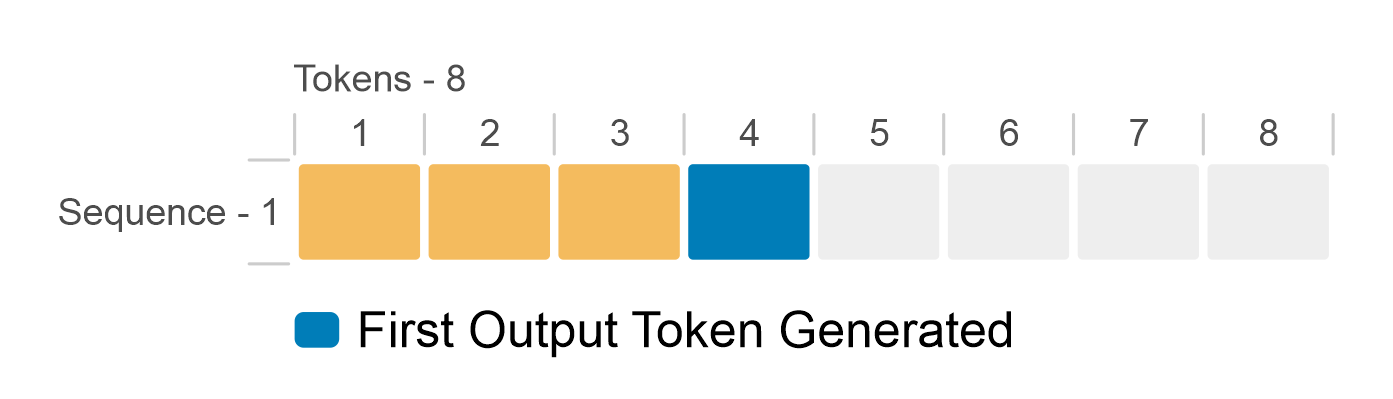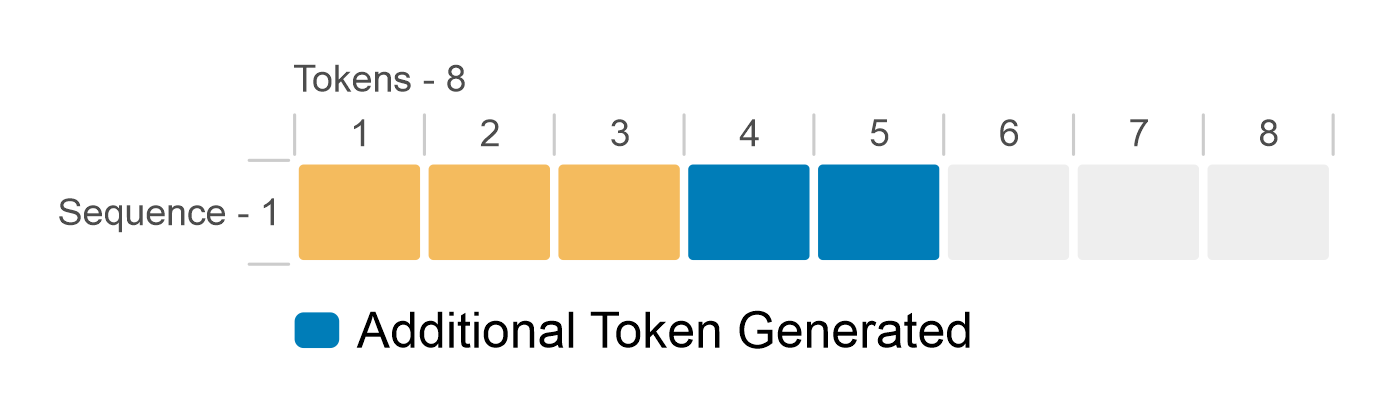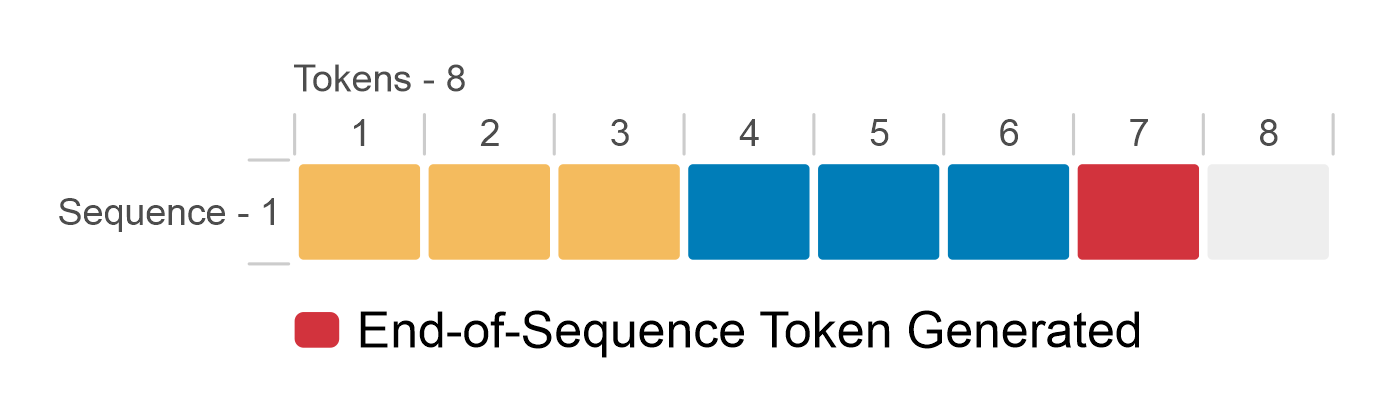




















.png?width=1000&height=600&name=Challenges%20in%20LLM%20Training%20and%20AI%20Inference%20Infographics%20(1).png)